Agent to Agent Testing Platform vs LLMWise
Side-by-side comparison to help you choose the right tool.
Agent to Agent Testing Platform
TestMu AI is the unified platform that autonomously validates AI agents for safety and performance across all.
Last updated: February 28, 2026
LLMWise
LLMWise is a single API that automatically routes your prompts to the best AI model from GPT, Claude, Gemini, and more.
Last updated: February 28, 2026
Visual Comparison
Agent to Agent Testing Platform
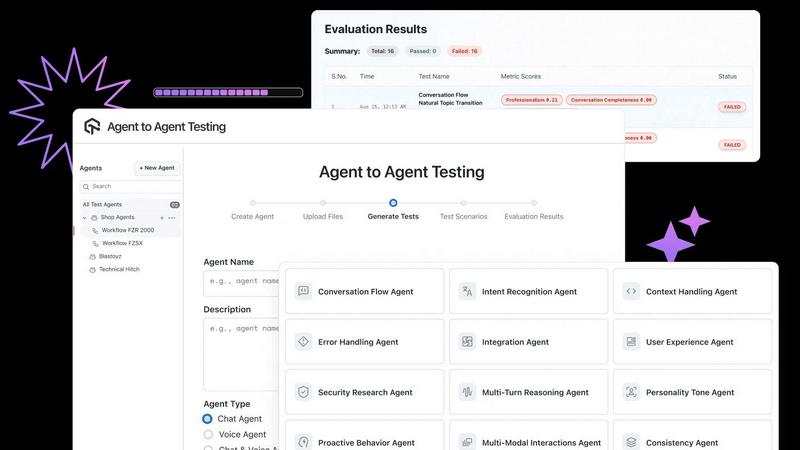
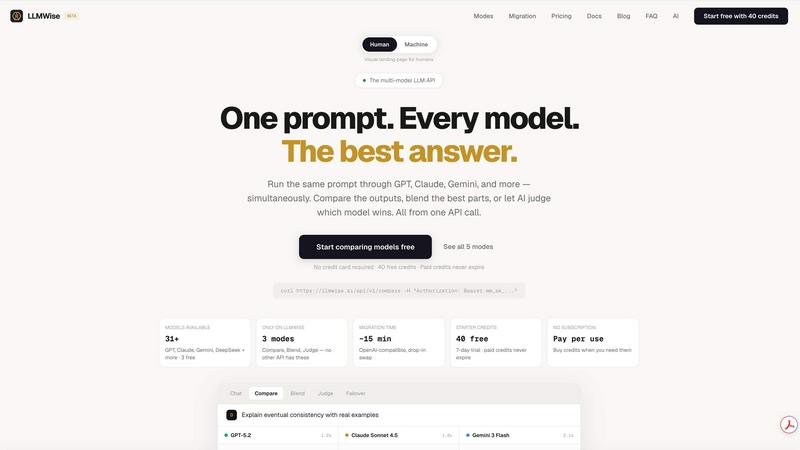
LLMWise
Feature Comparison
Agent to Agent Testing Platform
Autonomous Multi-Agent Test Generation
The platform employs a sophisticated ensemble of over 17 specialized AI agents, each designed to probe different aspects of an agent's performance. These synthetic agents autonomously generate and execute a vast array of test scenarios, simulating diverse personas and interaction patterns. This goes far beyond scripted tests, dynamically creating conversations to uncover subtle failures in intent recognition, reasoning, tone, escalation logic, and agent handoffs that would be missed by traditional or manual testing methods.
True Multi-Modal Understanding and Testing
Moving beyond text-only evaluation, the platform offers true multi-modal testing capabilities. Testers can define requirements or upload Product Requirement Documents (PRDs) that include diverse inputs like images, audio files, and video. The testing framework gauges the AI agent's expected output against these rich, real-world inputs, ensuring the agent under test can accurately interpret and respond to the full spectrum of communication modalities it will encounter in production.
Diverse Persona Simulation for Real-World Validation
To ensure AI agents perform effectively for all user types, the platform provides a library of diverse, configurable personas. Testers can leverage personas such as the "International Caller," "Digital Novice," or "Frustrated Customer" to simulate a wide range of end-user behaviors, cultural contexts, technical proficiencies, and emotional states. This feature guarantees that the agent's performance is robust and empathetic across the entire spectrum of its intended user base.
Actionable Evaluation with Risk Scoring
Following test execution, the platform delivers deep, actionable insights through detailed evaluation reports. It analyzes key business metrics, conversational flow, and interaction dynamics, providing scores on critical dimensions like effectiveness, accuracy, empathy, and professionalism. Crucially, it includes a regression testing suite with intelligent risk scoring, which highlights potential areas of concern and prioritizes critical issues, allowing teams to optimize their debugging and improvement efforts efficiently.
LLMWise
Intelligent Model Routing
LLMWise's smart routing engine acts as an expert conductor for your AI requests. You simply send a prompt, and the system intelligently analyzes it to select the most suitable model from its vast catalog. For instance, it can route complex code generation tasks to GPT-4o, creative writing to Claude Sonnet, and fast translations to Gemini Flash. This eliminates the guesswork and manual switching between different provider dashboards, ensuring you consistently get the highest quality output for any specific need without having to be an expert on every model's nuanced strengths.
Compare, Blend, and Judge Modes
This feature suite provides unparalleled control over AI outputs. The Compare mode allows you to run a single prompt across multiple models simultaneously, presenting their answers side-by-side with metrics on speed, cost, and token length for easy evaluation. Blend mode takes this further by querying several models and synthesizing their strongest elements into one superior, consolidated response. Judge mode introduces a meta-evaluation layer, where models can critique and score each other's outputs, providing deep insights into response quality and reasoning.
Resilient Circuit-Breaker Failover
LLMWise ensures your application's AI capabilities never go offline. It incorporates a robust circuit-breaker system that monitors the health and response times of all connected model providers. If a primary provider experiences downtime or latency issues, the system instantly and automatically reroutes requests to pre-configured backup models. This built-in redundancy guarantees high availability and reliability for production applications, protecting your service from external API failures without any manual intervention required.
Advanced Testing and Optimization Suite
The platform includes a comprehensive toolkit for performance and cost optimization. Developers can run benchmark suites and batch tests across models to measure accuracy, speed, and cost-effectiveness for their specific use cases. You can define and apply optimization policies that automatically prioritize factors like lowest cost, highest speed, or best reliability for different types of requests. Furthermore, automated regression checks help ensure that updates to models or prompts do not degrade the quality of your AI-powered features over time.
Use Cases
Agent to Agent Testing Platform
Pre-Production Validation of Customer Service Chatbots
Enterprises can deploy the platform to rigorously validate new or updated customer service chatbots before a full production rollout. By simulating thousands of synthetic customer interactions—from simple FAQ queries to complex, multi-issue troubleshooting—teams can identify failures in logic, inappropriate tones, hallucinated information, and compliance violations, ensuring a reliable and professional customer experience from day one.
Compliance and Safety Assurance for Voice Assistants
For voice-activated agents in sensitive industries like finance or healthcare, the platform is critical for ensuring compliance and safety. It autonomously tests for policy adherence, data privacy leaks, and biased responses within voice conversations. The framework validates proper escalation to human agents when necessary and checks that all verbal interactions meet strict regulatory and ethical standards, mitigating legal and reputational risk.
End-to-End Regression Testing for AI Agent Updates
Development teams can integrate the platform into their CI/CD pipelines to perform comprehensive regression testing every time an AI agent's model, prompts, or knowledge base is updated. The autonomous test suite re-runs a battery of scenarios to catch regressions in performance, intent recognition, or conversational flow. The integrated risk scoring helps teams quickly understand the impact of changes and prioritize fixes.
Performance Benchmarking Across Multiple AI Agents
Organizations evaluating different AI models or vendor solutions can use the platform as an objective benchmarking tool. By running the same battery of standardized test scenarios—assessing metrics like bias, toxicity, hallucination rates, and task effectiveness—against multiple agents, teams can gather quantitative, comparable data to make informed decisions about which AI agent best meets their quality and performance thresholds.
LLMWise
Development and Prototyping
Developers and startups can rapidly prototype AI features without financial commitment or complexity. With access to 30 permanently free models and trial credits, teams can experiment with different LLMs for tasks like generating code snippets, drafting documentation, or brainstorming product ideas. The Compare mode is invaluable for debugging prompt engineering strategies by instantly showing how different models interpret and respond to the same instruction, accelerating the development cycle.
Enterprise AI Application Resilience
For businesses running critical, customer-facing AI applications, LLMWise provides essential infrastructure reliability. By leveraging the intelligent router with failover capabilities, companies can ensure their chat assistants, content generators, or data analysis tools remain operational even if a major provider like OpenAI has an outage. Traffic is seamlessly shifted to alternative models like Claude or Gemini, maintaining uptime and user experience without service degradation.
Content Creation and Optimization
Marketing teams, writers, and content strategists can use LLMWise to produce higher-quality material efficiently. They can use Compare mode to generate multiple versions of a blog post intro from different models and select the best tone. For high-stakes content, Blend mode can merge the factual accuracy of one model with the engaging narrative style of another, creating a final piece that is both informative and compelling, surpassing what any single AI could produce alone.
Cost-Effective AI Operations
Organizations with existing API budgets can leverage LLMWise's BYOK (Bring Your Own Keys) support to consolidate their spending while gaining advanced orchestration features. This allows them to use their pre-purchased credits from OpenAI, Anthropic, or Google directly through LLMWise's smarter routing, often reducing costs by eliminating redundant subscriptions and ensuring each dollar is spent on the most cost-effective model for each task, as highlighted in the user testimonial.
Overview
About Agent to Agent Testing Platform
The Agent to Agent Testing Platform represents a fundamental evolution in quality assurance, purpose-built for the unique challenges of the agentic AI era. As AI systems transition from static, rule-based tools to dynamic, autonomous agents, traditional testing methodologies become obsolete. This platform is a first-of-its-kind, AI-native framework designed to validate the behavior, reliability, and safety of AI agents—including chatbots, voice assistants, and phone caller agents—within real-world, multi-turn conversational environments. It moves beyond simple prompt checks to evaluate complex interactions across chat, voice, and multimodal experiences, ensuring agents perform as intended before they are deployed into production. The core value proposition lies in its autonomous, multi-agent testing approach, which leverages a suite of specialized AI agents to simulate thousands of diverse user interactions, uncovering critical edge cases, policy violations, and long-tail failures that manual testing cannot feasibly detect. It is engineered for enterprises and development teams who are serious about deploying trustworthy, robust, and effective AI agentic systems at scale, providing a unified platform for comprehensive behavioral validation, risk assessment, and performance optimization.
About LLMWise
LLMWise is a sophisticated AI orchestration platform designed to liberate developers and businesses from the complexity and constraints of managing multiple large language model (LLM) providers. In an ecosystem where each AI model—from OpenAI's GPT and Anthropic's Claude to Google's Gemini and Meta's Llama—excels in different areas, LLMWise provides a single, unified API gateway to access over 62 models from 20+ leading providers. Its core intelligence lies in smart routing, which automatically matches each unique prompt to the optimal model for the task, whether it's coding, creative writing, translation, or analysis. Beyond simple access, LLMWise empowers users with powerful orchestration modes to compare outputs side-by-side, blend the best parts of multiple responses, and ensure unwavering resilience with automatic failover. Built for developers who demand the best AI performance for every task without vendor lock-in or subscription traps, LLMWise offers a flexible, pay-as-you-go model and supports bringing your own API keys (BYOK). It fundamentally transforms how teams integrate AI, turning a fragmented, costly process into a streamlined, intelligent, and reliable workflow.
Frequently Asked Questions
Agent to Agent Testing Platform FAQ
What makes Agent-to-Agent Testing different from traditional software QA?
Traditional QA is designed for deterministic, rule-based software with predictable inputs and outputs. Agentic AI, however, is non-deterministic and operates in open-ended conversational spaces. Agent-to-Agent Testing is built for this paradigm, using AI agents to test other AI agents through dynamic, multi-turn conversations. It evaluates emergent behaviors, contextual understanding, and ethical alignment—dimensions that static test scripts cannot effectively assess, providing validation for the autonomy and unpredictability inherent in modern AI systems.
What types of AI agents can be tested with this platform?
The platform is designed as a unified testing solution for a wide range of AI agent implementations. This includes text-based conversational agents (chatbots), voice assistants (like IVR systems or smart device assistants), phone caller agents that handle inbound/outbound calls, and hybrid multimodal agents that process combinations of text, image, audio, and video inputs. Essentially, any AI system that engages in interactive dialogue with users can be validated.
How does the platform handle test scenario creation?
Test scenario creation is both automated and customizable. The platform's core AI agents can autonomously generate diverse, production-like test cases based on high-level requirements or uploaded documentation. Additionally, users have access to a library of hundreds of pre-built scenarios and can create fully custom scenarios tailored to specific business processes, user journeys, or edge cases they need to validate, offering flexibility and comprehensive coverage.
Can the platform integrate with existing development workflows?
Yes, the platform is built for seamless integration into modern DevOps and MLOps pipelines. It offers native integration with TestMu AI's HyperExecute for large-scale, parallel test execution in the cloud, fitting directly into CI/CD cycles. This allows teams to automatically trigger agent validation suites on every code or model commit, receiving actionable evaluation reports and risk scores within minutes to maintain continuous quality assurance.
LLMWise FAQ
How does the pricing work?
LLMWise operates on a transparent, pay-as-you-go credit system with no monthly subscriptions. You can start with 20 free trial credits that never expire. For paid usage, you purchase credit packs which are consumed based on the model you use, with costs mirroring the underlying provider's pricing. Crucially, the platform offers 30 models that are permanently free to use at 0 credits, ideal for testing, fallback, and everyday prompts. You also have the option to bring your own API keys (BYOK) and pay providers directly, only using LLMWise for its routing and orchestration intelligence.
What is Smart Routing and how does it choose a model?
Smart Routing is LLMWise's automated system that selects the best LLM for your specific prompt. While you can manually select any model, the router uses intelligent heuristics and configurable rules to make a recommendation. It considers factors like the task type (e.g., coding, creative writing, summarization), desired output length, and your optimization policy (e.g., prioritize speed, cost, or quality). You can refine its behavior over time based on your own benchmark results and preferences.
Can I use my existing API keys?
Yes, LLMWise fully supports a Bring Your Own Keys (BYOK) model. You can integrate your existing API keys from providers like OpenAI, Anthropic, and Google. When using BYOK, you are billed directly by those providers according to their standard rates, and LLMWise does not charge any markup on the model usage. You only pay for LLMWise's orchestration features if you exceed the free tier of requests, allowing for significant cost control and flexibility.
What happens if an AI provider goes down?
LLMWise is built for resilience. It includes a circuit-breaker failover system that continuously monitors all connected providers. If it detects downtime, errors, or high latency from your primary model, it will automatically and instantly reroute your application's requests to a pre-defined backup model from a different provider. This ensures your application's AI features remain available and responsive, preventing any disruption to your end-users without requiring you to manually switch APIs or implement complex error-handling code.
Alternatives
Agent to Agent Testing Platform Alternatives
Agent to Agent Testing Platform is a pioneering solution in the AI-native quality assurance category, specifically designed to validate the complex, autonomous behavior of AI agents across diverse channels like chat, voice, and phone. It addresses the critical need for a dynamic testing framework that traditional, static software QA methods cannot fulfill. Users often explore alternatives for various reasons, including budget constraints, specific feature requirements not covered by a single platform, or the need for a solution that integrates seamlessly with their existing technology stack and development workflows. The search for the right tool is a common step in the procurement process. When evaluating alternatives, it is crucial to look for a solution that offers comprehensive, multi-turn conversation validation, scalable automated testing capabilities, and robust security and compliance risk detection. The ideal platform should provide deep behavioral analysis beyond simple prompt checks, ensuring AI agents perform reliably and safely in production environments.
LLMWise Alternatives
LLMWise is a unified API platform in the AI assistants category, designed to streamline access to multiple large language models like GPT, Claude, and Gemini. It uses intelligent auto-routing to select the optimal model for each specific prompt, aiming to deliver the best possible output for every task without requiring users to manage separate provider integrations. Users may explore alternatives for various reasons, including specific budget constraints, the need for different feature sets like advanced analytics or custom model fine-tuning, or a preference for platform-specific ecosystems. Some may seek simpler solutions for a single model or require enterprise-grade support structures that align with their organizational workflows. When evaluating alternatives, key considerations include the range of supported AI models, the sophistication of routing and failover logic, overall cost transparency and structure, and the depth of developer tools for testing and optimization. The ideal choice balances simplicity, performance, and reliability to match the unique technical and business requirements of the project.