Agenta vs OpenMark AI
Side-by-side comparison to help you choose the right tool.
Agenta is the open-source platform that helps teams build and manage reliable AI applications together.
Last updated: March 1, 2026
OpenMark AI instantly benchmarks over 100 AI models on your specific task to find the optimal balance of cost, speed, and quality.
Last updated: March 26, 2026
Visual Comparison
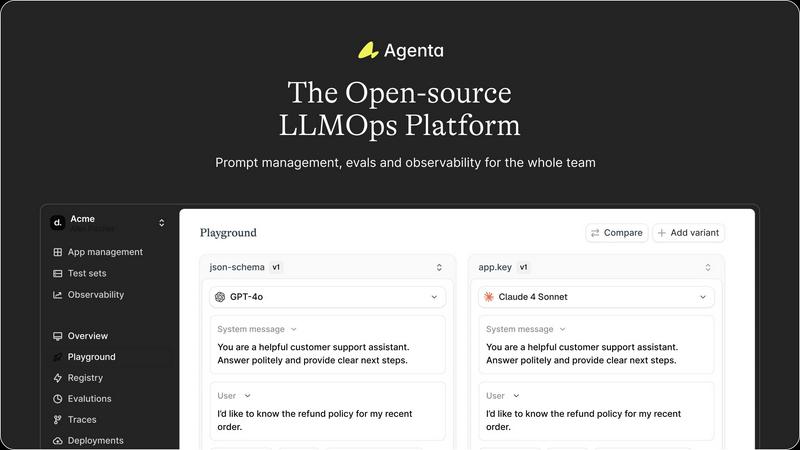
Agenta
OpenMark AI

Feature Comparison
Agenta
Unified Playground for Experimentation
Agenta provides a centralized playground where teams can experiment with different prompts, models, and parameters side-by-side in a single interface. This eliminates the need for scattered tools and documents, allowing for direct comparison and rapid iteration. Foundational to its design is complete version history for all prompts, ensuring every change is tracked and reversible, fostering a systematic approach to development rather than ad-hoc "vibe testing."
Comprehensive Evaluation Framework
The platform replaces guesswork with evidence through a robust evaluation system. Teams can create automated test suites using LLM-as-a-judge, custom code evaluators, or built-in metrics. Crucially, Agenta enables evaluation of full agentic traces, assessing each intermediate reasoning step, not just the final output. It also seamlessly integrates human evaluation workflows, allowing domain experts and product managers to provide qualitative feedback directly within the platform.
Production Observability and Debugging
Agenta offers deep observability by tracing every LLM request in production, making it possible to pinpoint exact failure points when issues arise. Teams can annotate these traces collaboratively and, with a single click, turn any problematic trace into a test case for the playground, closing the feedback loop. This capability is augmented by live monitoring to detect performance regressions and gather real user feedback.
Collaborative Workflow for Cross-Functional Teams
Designed as a single source of truth, Agenta breaks down silos between developers, product managers, and domain experts. It provides a safe, code-free UI for experts to edit and experiment with prompts. The platform ensures full parity between its API and UI, enabling both programmatic and manual workflows to integrate into one central hub, empowering the entire team to participate in experiments, evaluations, and debugging.
OpenMark AI
Plain Language Task Benchmarking
OpenMark AI removes the barrier of technical complexity by allowing users to define their test scenarios using simple, descriptive language. You don't need to write complex scripts or structured prompts; you just describe what you want the AI to do, such as "extract dates and product names from customer service emails" or "generate three taglines for a new productivity app." The platform intelligently configures the benchmark, enabling rapid, iterative testing of your actual workflow without any coding required.
Multi-Model Comparison in One Session
The platform's core strength is its ability to run your described task against a massive selection of LLMs simultaneously. Instead of manually testing models one by one across different interfaces and dashboards, you launch a single benchmark job. OpenMark AI coordinates real API calls to all selected models, presenting the results in a unified dashboard for immediate, apples-to-apples comparison across quality scores, cost, and speed.
Variance and Stability Analysis
OpenMark AI provides deep insight into model reliability by running your task multiple times per model. This feature measures output consistency, showing you the variance in responses. It answers the critical question: "Will this model perform consistently when deployed at scale?" This focus on stability, beyond a single output, helps identify models that are robust and dependable versus those that are unpredictable.
Integrated Cost-Per-Request Calculation
Every benchmark includes precise, real-time calculation of the cost incurred for each API call to each model. This goes beyond listed token prices, showing you the actual expense of achieving a certain quality level for your specific task. This allows for true cost-efficiency analysis, helping you select a model that delivers the required performance at a sustainable operational cost, optimizing your AI budget effectively.
Use Cases
Agenta
Streamlining Enterprise LLM Application Development
Large organizations developing customer-facing AI assistants or internal copilots use Agenta to bring structure to their development process. It enables cross-functional teams to collaborate efficiently, moving from disjointed prototyping in Slack and sheets to a governed lifecycle with version control, systematic evaluation against business metrics, and smooth handoff from experimentation to stable, observable deployment.
Implementing Rigorous AI Quality Assurance
Teams that require high reliability and consistency, such as those in legal, financial, or healthcare sectors, leverage Agenta to build a rigorous QA pipeline for their LLM applications. They use the platform to create comprehensive evaluation datasets, run automated and human-in-the-loop evaluations on every proposed change, and monitor production performance to ensure no regressions slip through, thereby building evidence-based trust in their AI systems.
Debugging and Optimizing Complex AI Agents
Developers building sophisticated multi-step agents with frameworks like LangChain use Agenta's observability features to debug complex failures. By examining detailed traces of each step in an agent's reasoning, teams can quickly identify where a chain fails, save those instances as tests, and iteratively refine prompts and logic in the playground until robustness is achieved.
Enabling Domain Expert Collaboration
Companies where subject matter experts (e.g., doctors, lawyers, analysts) are crucial for validating AI output use Agenta to democratize the development process. The platform's intuitive UI allows these non-technical experts to directly participate in prompt engineering, run evaluations, and provide annotated feedback on real production traces, ensuring the AI aligns closely with specialized domain knowledge.
OpenMark AI
Pre-Deployment Model Selection for New Features
Development teams building a new AI-powered feature, such as a content summarizer or a customer support chatbot, can use OpenMark to empirically determine the best foundational model. By benchmarking prototypes of their exact task, they can select the optimal model based on a combination of accuracy, response time, and cost before committing to an integration, reducing risk and technical debt.
Validating Model Performance for Critical Workflows
For companies with existing AI integrations in sensitive areas like data extraction, legal document review, or medical research assistance, OpenMark serves as a validation suite. Teams can regularly benchmark their current model against new alternatives to ensure they are still using the most effective and cost-efficient option, or to test the impact of model updates on their specific outputs.
Optimizing Agentic or Multi-Step AI Systems
When designing complex AI agents that involve routing, classification, or chaining multiple LLM calls, choosing the right model for each step is vital. Engineers can use OpenMark to benchmark subtasks—like intent classification or query reformulation—to find specialized models that improve overall system performance and reliability while controlling cascading costs.
Academic and Industrial AI Research
Researchers and analysts focused on LLM capabilities can utilize OpenMark's structured testing environment to conduct comparative studies. The platform's ability to run consistent prompts across many models and measure variance provides robust, reproducible data for analyzing model strengths, weaknesses, and evolution across different task types and difficulty levels.
Overview
About Agenta
Agenta is an open-source LLMOps platform engineered to solve the fundamental challenge of building reliable, production-grade applications with large language models. It serves as a unified operating system for AI development teams, bridging the critical gap between experimental prototyping and stable deployment. The platform is designed for collaborative teams comprising developers, product managers, and subject matter experts who need to move beyond scattered, ad-hoc workflows. Its core value proposition lies in centralizing the entire LLM application lifecycle—from prompt experimentation and rigorous evaluation to comprehensive observability—into a single, coherent platform. By replacing guesswork with evidence-based processes, Agenta empowers organizations to systematically iterate on prompts, validate changes against automated and human evaluations, and swiftly debug issues using real production data. It is model-agnostic and framework-friendly, integrating seamlessly with popular tools like LangChain and LlamaIndex, thereby preventing vendor lock-in and providing the essential infrastructure to implement LLMOps best practices at scale. Agenta transforms the chaotic process of AI development into a structured, collaborative, and data-driven discipline.
About OpenMark AI
OpenMark AI is a sophisticated, web-based platform designed to revolutionize how developers and product teams select and validate large language models (LLMs) for their specific applications. It moves beyond theoretical benchmarks and marketing claims by enabling task-level, real-world performance testing. The core premise is simple yet powerful: users describe their exact task in plain language, and OpenMark AI executes that prompt against a vast catalog of over 100 models in a single, unified session. This process generates comprehensive, side-by-side comparisons based on actual API calls, measuring critical metrics like scored output quality, cost per request, latency, and—crucially—output stability across multiple runs. By revealing variance and consistency, not just a single "lucky" output, OpenMark provides the empirical data needed to make informed, cost-efficient decisions before shipping an AI feature. It eliminates the logistical headache of managing multiple API keys and configurations, offering a hosted, credit-based system that grants immediate access to models from leading providers like OpenAI, Anthropic, and Google. Ultimately, OpenMark AI is built for professionals who prioritize finding the optimal balance between performance, reliability, and operational cost for their unique use case.
Frequently Asked Questions
Agenta FAQ
Is Agenta truly open-source?
Yes, Agenta is a fully open-source platform. The core codebase is publicly available on GitHub, allowing users to inspect, modify, and contribute to the software. This open model ensures transparency, prevents vendor lock-in, and allows the community to influence the product's roadmap while providing the freedom to self-host the platform.
How does Agenta integrate with existing AI stacks?
Agenta is designed to be model-agnostic and framework-friendly. It offers seamless integrations with popular LLM providers (like OpenAI), orchestration frameworks (such as LangChain and LlamaIndex), and can be extended with custom evaluators. This flexibility allows teams to incorporate Agenta into their existing workflows without disrupting their current toolchain.
Can non-technical team members really use Agenta effectively?
Absolutely. A key design principle of Agenta is to bridge the gap between technical and non-technical roles. Product managers and domain experts can use the web UI to experiment with prompts in the playground, configure and view evaluation results, and annotate production traces—all without writing a single line of code, fostering true collaborative development.
What is the difference between Agenta and simple prompt management tools?
While basic tools might help version prompts, Agenta provides a complete LLMOps lifecycle platform. It combines prompt management with integrated evaluation (automated and human), full production observability with trace debugging, and collaborative workflows. This holistic approach ensures that prompts are not just managed but are systematically improved, validated, and monitored within the context of the entire application.
OpenMark AI FAQ
How does OpenMark AI calculate the quality score for model outputs?
OpenMark AI employs a sophisticated, automated evaluation system that scores model outputs based on their adherence to your task's instructions and desired outcome. While the exact methodology is proprietary, it typically involves a combination of metrics that may include semantic similarity, keyword presence, factual accuracy checks (where applicable), and structured format compliance. This provides a quantitative measure of how "correct" or suitable each model's response is for your specific benchmark.
Do I need API keys for OpenAI, Anthropic, or other model providers?
No, you do not need to provide or configure any external API keys. OpenMark AI operates on a credit-based system. You purchase credits through the platform, and these credits are used to pay for the underlying API calls when you run benchmarks. This hosted approach simplifies access, manages rate limits, and provides a single, unified cost structure for testing across the entire model catalog.
What is the difference between a "task" and a "benchmark" in OpenMark?
A "Task" is your defined objective—the instructions and any example inputs you create in plain language. A "Benchmark" is the execution of that task. When you run a benchmark, you select which models to test against your task, configure the number of repeat runs for stability analysis, and launch the job. The benchmark results then show how each model performed on that specific task.
Can I use OpenMark to test private or fine-tuned models?
Currently, OpenMark AI focuses on providing access to its extensive catalog of publicly available, state-of-the-art models from major providers. The platform is designed for comparative benchmarking of these off-the-shelf models. Support for testing privately hosted or custom fine-tuned models is not a standard feature, as the platform's value lies in its managed, unified access to a wide array of pre-existing models for direct comparison.
Alternatives
Agenta Alternatives
Agenta is an open-source LLMOps platform designed to help development teams build and manage reliable AI applications. It falls into the category of development tools focused on the operational lifecycle of large language models, providing a unified system for experimentation, evaluation, and deployment. Users may explore alternatives for various reasons, including specific budget constraints, the need for different feature sets like advanced monitoring or native CI/CD integration, or a preference for a managed service over self-hosted open-source software. Organizational requirements around scalability, security compliance, and existing tech stack compatibility also drive the search for other solutions. When evaluating alternatives, key considerations should include the platform's approach to collaborative experimentation, the robustness of its evaluation and testing frameworks, and its observability capabilities for production applications. The ideal tool should align with your team's workflow, support the LLM frameworks you use, and provide a clear path from prototype to stable, monitored deployment.
OpenMark AI Alternatives
OpenMark AI is a specialized developer tool designed for task-level benchmarking of large language models. It allows teams to run real prompts against a wide catalog of LLMs in a single session, comparing critical metrics like cost, latency, quality, and output stability to inform pre-deployment decisions. Users may explore alternatives for various reasons, such as differing budget constraints, the need for on-premise deployment, or a requirement for more granular technical controls beyond hosted benchmarking. Some may seek tools integrated directly into their CI/CD pipeline or those offering different model access or pricing structures. When evaluating other solutions, key considerations include the scope of supported models, the authenticity of performance data, the depth of analysis on cost versus quality, and the overall workflow efficiency. The ideal tool should provide transparent, actionable insights that align with your specific development stage and operational requirements.