Agenta
Agenta is the open-source platform that helps teams build and manage reliable AI applications together.
About Agenta
Agenta is an open-source LLMOps platform engineered to solve the fundamental challenge of building reliable, production-grade applications with large language models. It serves as a unified operating system for AI development teams, bridging the critical gap between experimental prototyping and stable deployment. The platform is designed for collaborative teams comprising developers, product managers, and subject matter experts who need to move beyond scattered, ad-hoc workflows. Its core value proposition lies in centralizing the entire LLM application lifecycle—from prompt experimentation and rigorous evaluation to comprehensive observability—into a single, coherent platform. By replacing guesswork with evidence-based processes, Agenta empowers organizations to systematically iterate on prompts, validate changes against automated and human evaluations, and swiftly debug issues using real production data. It is model-agnostic and framework-friendly, integrating seamlessly with popular tools like LangChain and LlamaIndex, thereby preventing vendor lock-in and providing the essential infrastructure to implement LLMOps best practices at scale. Agenta transforms the chaotic process of AI development into a structured, collaborative, and data-driven discipline.
Features of Agenta
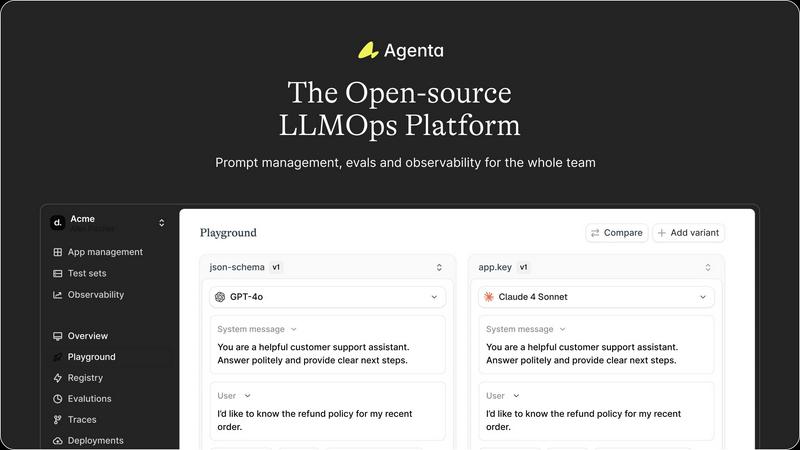
Unified Playground for Experimentation
Agenta provides a centralized playground where teams can experiment with different prompts, models, and parameters side-by-side in a single interface. This eliminates the need for scattered tools and documents, allowing for direct comparison and rapid iteration. Foundational to its design is complete version history for all prompts, ensuring every change is tracked and reversible, fostering a systematic approach to development rather than ad-hoc "vibe testing."
Comprehensive Evaluation Framework
The platform replaces guesswork with evidence through a robust evaluation system. Teams can create automated test suites using LLM-as-a-judge, custom code evaluators, or built-in metrics. Crucially, Agenta enables evaluation of full agentic traces, assessing each intermediate reasoning step, not just the final output. It also seamlessly integrates human evaluation workflows, allowing domain experts and product managers to provide qualitative feedback directly within the platform.
Production Observability and Debugging
Agenta offers deep observability by tracing every LLM request in production, making it possible to pinpoint exact failure points when issues arise. Teams can annotate these traces collaboratively and, with a single click, turn any problematic trace into a test case for the playground, closing the feedback loop. This capability is augmented by live monitoring to detect performance regressions and gather real user feedback.
Collaborative Workflow for Cross-Functional Teams
Designed as a single source of truth, Agenta breaks down silos between developers, product managers, and domain experts. It provides a safe, code-free UI for experts to edit and experiment with prompts. The platform ensures full parity between its API and UI, enabling both programmatic and manual workflows to integrate into one central hub, empowering the entire team to participate in experiments, evaluations, and debugging.
Use Cases of Agenta
Streamlining Enterprise LLM Application Development
Large organizations developing customer-facing AI assistants or internal copilots use Agenta to bring structure to their development process. It enables cross-functional teams to collaborate efficiently, moving from disjointed prototyping in Slack and sheets to a governed lifecycle with version control, systematic evaluation against business metrics, and smooth handoff from experimentation to stable, observable deployment.
Implementing Rigorous AI Quality Assurance
Teams that require high reliability and consistency, such as those in legal, financial, or healthcare sectors, leverage Agenta to build a rigorous QA pipeline for their LLM applications. They use the platform to create comprehensive evaluation datasets, run automated and human-in-the-loop evaluations on every proposed change, and monitor production performance to ensure no regressions slip through, thereby building evidence-based trust in their AI systems.
Debugging and Optimizing Complex AI Agents
Developers building sophisticated multi-step agents with frameworks like LangChain use Agenta's observability features to debug complex failures. By examining detailed traces of each step in an agent's reasoning, teams can quickly identify where a chain fails, save those instances as tests, and iteratively refine prompts and logic in the playground until robustness is achieved.
Enabling Domain Expert Collaboration
Companies where subject matter experts (e.g., doctors, lawyers, analysts) are crucial for validating AI output use Agenta to democratize the development process. The platform's intuitive UI allows these non-technical experts to directly participate in prompt engineering, run evaluations, and provide annotated feedback on real production traces, ensuring the AI aligns closely with specialized domain knowledge.
Frequently Asked Questions
Is Agenta truly open-source?
Yes, Agenta is a fully open-source platform. The core codebase is publicly available on GitHub, allowing users to inspect, modify, and contribute to the software. This open model ensures transparency, prevents vendor lock-in, and allows the community to influence the product's roadmap while providing the freedom to self-host the platform.
How does Agenta integrate with existing AI stacks?
Agenta is designed to be model-agnostic and framework-friendly. It offers seamless integrations with popular LLM providers (like OpenAI), orchestration frameworks (such as LangChain and LlamaIndex), and can be extended with custom evaluators. This flexibility allows teams to incorporate Agenta into their existing workflows without disrupting their current toolchain.
Can non-technical team members really use Agenta effectively?
Absolutely. A key design principle of Agenta is to bridge the gap between technical and non-technical roles. Product managers and domain experts can use the web UI to experiment with prompts in the playground, configure and view evaluation results, and annotate production traces—all without writing a single line of code, fostering true collaborative development.
What is the difference between Agenta and simple prompt management tools?
While basic tools might help version prompts, Agenta provides a complete LLMOps lifecycle platform. It combines prompt management with integrated evaluation (automated and human), full production observability with trace debugging, and collaborative workflows. This holistic approach ensures that prompts are not just managed but are systematically improved, validated, and monitored within the context of the entire application.
Explore more in this category:
Similar to Agenta
Social Fetch
Replace your social media scrapers with one REST API. Scrape TikTok, Instagram, YouTube, Facebook, Reddit, and Threads profiles, posts, and metrics.
Headless Domains
Headless Domains gives AI agents a persistent, verifiable web identity they can use across apps, APIs, and marketplaces to prove who they are and.
ProcessSpy
ProcessSpy is a powerful Mac process monitor that delivers in-depth insights and advanced filtering for seamless system management.
Claw Messenger
Claw Messenger provides your AI agent with its own iMessage number for instant, seamless communication without needing a Mac.