Agenta vs Fallom
Side-by-side comparison to help you choose the right tool.
Agenta is the open-source platform that helps teams build and manage reliable AI applications together.
Last updated: March 1, 2026
Fallom provides complete observability and control for your AI agents and LLM applications.
Last updated: February 28, 2026
Visual Comparison
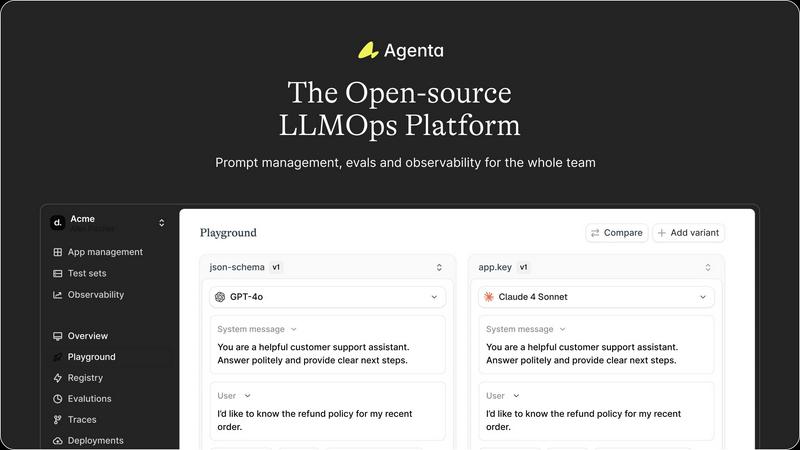
Agenta
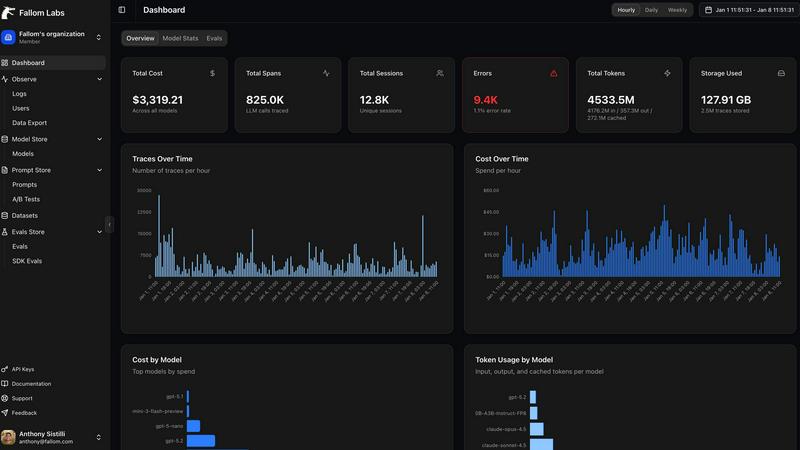
Fallom
Feature Comparison
Agenta
Unified Playground for Experimentation
Agenta provides a centralized playground where teams can experiment with different prompts, models, and parameters side-by-side in a single interface. This eliminates the need for scattered tools and documents, allowing for direct comparison and rapid iteration. Foundational to its design is complete version history for all prompts, ensuring every change is tracked and reversible, fostering a systematic approach to development rather than ad-hoc "vibe testing."
Comprehensive Evaluation Framework
The platform replaces guesswork with evidence through a robust evaluation system. Teams can create automated test suites using LLM-as-a-judge, custom code evaluators, or built-in metrics. Crucially, Agenta enables evaluation of full agentic traces, assessing each intermediate reasoning step, not just the final output. It also seamlessly integrates human evaluation workflows, allowing domain experts and product managers to provide qualitative feedback directly within the platform.
Production Observability and Debugging
Agenta offers deep observability by tracing every LLM request in production, making it possible to pinpoint exact failure points when issues arise. Teams can annotate these traces collaboratively and, with a single click, turn any problematic trace into a test case for the playground, closing the feedback loop. This capability is augmented by live monitoring to detect performance regressions and gather real user feedback.
Collaborative Workflow for Cross-Functional Teams
Designed as a single source of truth, Agenta breaks down silos between developers, product managers, and domain experts. It provides a safe, code-free UI for experts to edit and experiment with prompts. The platform ensures full parity between its API and UI, enabling both programmatic and manual workflows to integrate into one central hub, empowering the entire team to participate in experiments, evaluations, and debugging.
Fallom
End-to-End LLM Tracing
Fallom provides complete, real-time observability for every LLM call and AI agent interaction. It captures the full context of each operation, including the exact input prompts, model-generated outputs, all intermediate tool and function calls with their arguments and results, token consumption, latency breakdowns, and precise cost data. This granular, waterfall-style tracing is essential for understanding complex, multi-step workflows, diagnosing failures, and identifying performance bottlenecks that simple logs cannot reveal.
Enterprise Compliance & Audit Trails
The platform is built from the ground up to support the stringent requirements of regulated industries. Fallom automatically generates immutable, detailed audit trails for every AI interaction, providing the necessary documentation for compliance with frameworks like the EU AI Act, SOC 2, and GDPR. Features include comprehensive input/output logging, model versioning tracking, user consent recording, and configurable privacy modes that allow for metadata-only logging to protect sensitive data while maintaining full telemetry.
Cost Attribution & Spend Management
Fallom delivers unparalleled transparency into AI operational costs. It automatically attributes spend across multiple dimensions, including per model, per API call, per user, per team, or per customer. This allows for accurate budgeting, internal chargebacks, and identifying cost-optimization opportunities. Real-time dashboards and visualizations help teams monitor their monthly burn, compare model costs, and control unpredictable expenses before they escalate.
Model Management & A/B Testing
The platform enables safe and data-driven model evolution. Teams can conduct live A/B tests by splitting traffic between different models or prompt versions, comparing their performance on key metrics like cost, latency, and quality evaluations. Coupled with a integrated Prompt Store for version control, this allows organizations to systematically roll out improvements, validate new models in production, and instantly deploy winning configurations with confidence.
Use Cases
Agenta
Streamlining Enterprise LLM Application Development
Large organizations developing customer-facing AI assistants or internal copilots use Agenta to bring structure to their development process. It enables cross-functional teams to collaborate efficiently, moving from disjointed prototyping in Slack and sheets to a governed lifecycle with version control, systematic evaluation against business metrics, and smooth handoff from experimentation to stable, observable deployment.
Implementing Rigorous AI Quality Assurance
Teams that require high reliability and consistency, such as those in legal, financial, or healthcare sectors, leverage Agenta to build a rigorous QA pipeline for their LLM applications. They use the platform to create comprehensive evaluation datasets, run automated and human-in-the-loop evaluations on every proposed change, and monitor production performance to ensure no regressions slip through, thereby building evidence-based trust in their AI systems.
Debugging and Optimizing Complex AI Agents
Developers building sophisticated multi-step agents with frameworks like LangChain use Agenta's observability features to debug complex failures. By examining detailed traces of each step in an agent's reasoning, teams can quickly identify where a chain fails, save those instances as tests, and iteratively refine prompts and logic in the playground until robustness is achieved.
Enabling Domain Expert Collaboration
Companies where subject matter experts (e.g., doctors, lawyers, analysts) are crucial for validating AI output use Agenta to democratize the development process. The platform's intuitive UI allows these non-technical experts to directly participate in prompt engineering, run evaluations, and provide annotated feedback on real production traces, ensuring the AI aligns closely with specialized domain knowledge.
Fallom
Debugging Complex AI Agent Workflows
When a multi-step AI agent—involving sequential LLM calls, database queries, and API tool usage—fails or behaves unexpectedly, traditional logging is insufficient. Fallom’s end-to-end tracing allows developers to visually follow the entire execution path, inspect the state at each step, see the exact inputs and outputs of every tool call, and pinpoint precisely where and why an error occurred, drastically reducing mean time to resolution (MTTR).
Ensuring Regulatory Compliance for AI Products
For companies operating in finance, healthcare, or any sector bound by regulations like the EU AI Act, demonstrating accountability is non-negotiable. Fallom provides the necessary audit trail, documenting every AI decision, the model version used, user interactions, and data handling. This creates a verifiable record that proves due diligence, supports compliance audits, and helps build trustworthy, transparent AI systems.
Optimizing AI Performance and Cost Efficiency
Organizations scaling their AI usage often face ballooning, opaque costs and latency issues. Fallom’s detailed metrics allow teams to analyze which models, prompts, or users are driving the highest spend and latency. Engineers can use this data to optimize prompts, switch to more cost-effective models for certain tasks, cache frequent responses, and right-size their AI infrastructure, leading to direct improvements in unit economics and user experience.
Managing Production AI Rollouts and Experiments
Safely introducing a new LLM model or a major prompt update into a live application is risky. Fallom’s A/B testing and evaluation framework allows product teams to roll out changes to a small percentage of traffic, compare the new version’s performance against the baseline on real-world data, and monitor for regressions in accuracy or hallucinations before committing to a full deployment, minimizing operational risk.
Overview
About Agenta
Agenta is an open-source LLMOps platform engineered to solve the fundamental challenge of building reliable, production-grade applications with large language models. It serves as a unified operating system for AI development teams, bridging the critical gap between experimental prototyping and stable deployment. The platform is designed for collaborative teams comprising developers, product managers, and subject matter experts who need to move beyond scattered, ad-hoc workflows. Its core value proposition lies in centralizing the entire LLM application lifecycle—from prompt experimentation and rigorous evaluation to comprehensive observability—into a single, coherent platform. By replacing guesswork with evidence-based processes, Agenta empowers organizations to systematically iterate on prompts, validate changes against automated and human evaluations, and swiftly debug issues using real production data. It is model-agnostic and framework-friendly, integrating seamlessly with popular tools like LangChain and LlamaIndex, thereby preventing vendor lock-in and providing the essential infrastructure to implement LLMOps best practices at scale. Agenta transforms the chaotic process of AI development into a structured, collaborative, and data-driven discipline.
About Fallom
Fallom is the definitive AI-native observability platform engineered for the complex realities of production-level large language model (LLM) and AI agent workloads. As artificial intelligence transitions from experimental prototypes to being deeply integrated into core business operations, the need for comprehensive visibility and control becomes paramount. Fallom answers this critical need by providing engineering, product, and compliance teams with the tools required to operate with confidence. It transcends basic logging by offering end-to-end tracing for every LLM interaction, capturing a complete picture that includes the full prompt, the generated output, every tool and function call, token usage, latency metrics, and precise per-call cost data. This granular insight is indispensable for debugging intricate, multi-step agentic workflows, optimizing performance for speed and cost, and governing unpredictable AI spend. Built on the open standard of OpenTelemetry, Fallom ensures teams are never locked into a proprietary ecosystem, offering a unified SDK for instrumentation in minutes. Designed for enterprise scale and rigor, it provides not just technical observability but also the session-level context, detailed audit trails, model versioning, and user consent tracking necessary to meet stringent compliance standards like the EU AI Act, SOC 2, and GDPR. Fallom empowers organizations to build, deploy, and scale reliable, governable, and cost-effective AI applications.
Frequently Asked Questions
Agenta FAQ
Is Agenta truly open-source?
Yes, Agenta is a fully open-source platform. The core codebase is publicly available on GitHub, allowing users to inspect, modify, and contribute to the software. This open model ensures transparency, prevents vendor lock-in, and allows the community to influence the product's roadmap while providing the freedom to self-host the platform.
How does Agenta integrate with existing AI stacks?
Agenta is designed to be model-agnostic and framework-friendly. It offers seamless integrations with popular LLM providers (like OpenAI), orchestration frameworks (such as LangChain and LlamaIndex), and can be extended with custom evaluators. This flexibility allows teams to incorporate Agenta into their existing workflows without disrupting their current toolchain.
Can non-technical team members really use Agenta effectively?
Absolutely. A key design principle of Agenta is to bridge the gap between technical and non-technical roles. Product managers and domain experts can use the web UI to experiment with prompts in the playground, configure and view evaluation results, and annotate production traces—all without writing a single line of code, fostering true collaborative development.
What is the difference between Agenta and simple prompt management tools?
While basic tools might help version prompts, Agenta provides a complete LLMOps lifecycle platform. It combines prompt management with integrated evaluation (automated and human), full production observability with trace debugging, and collaborative workflows. This holistic approach ensures that prompts are not just managed but are systematically improved, validated, and monitored within the context of the entire application.
Fallom FAQ
How does Fallom differ from traditional application monitoring tools?
Traditional Application Performance Monitoring (APM) tools are built for conventional software, focusing on metrics like CPU usage, HTTP request latency, and database queries. They lack the native concepts required for AI: prompts, completions, token usage, model costs, and multi-step agent reasoning. Fallom is purpose-built for the AI stack, providing semantic understanding of LLM calls, tool executions, and the unique cost and compliance dimensions of generative AI, offering insights that generic tools cannot.
Is my data secure and private with Fallom?
Yes, Fallom is designed with enterprise-grade security and privacy controls. It offers a configurable Privacy Mode that allows you to disable full content capture for sensitive interactions, logging only metadata (like timings and token counts) while still providing crucial observability. Data is encrypted in transit and at rest, and the platform's compliance features, including audit trails and access controls, help you meet stringent data protection standards like GDPR.
How difficult is it to integrate Fallom into my existing AI application?
Integration is designed to be straightforward and fast. Fallom provides a unified SDK based on the OpenTelemetry standard. For most applications, developers can instrument their LLM calls and tool usage in under five minutes. The platform works with all major model providers (OpenAI, Anthropic, Google, etc.) and AI frameworks, ensuring there is no vendor lock-in and you can maintain your existing AI infrastructure.
Can Fallom help me reduce my overall LLM API costs?
Absolutely. Cost optimization is a core strength. By providing detailed, per-call cost attribution, Fallom helps you identify the most expensive operations, users, or model choices. You can analyze patterns, A/B test more cost-effective models for specific tasks, optimize inefficient prompts that consume excessive tokens, and set up alerts for unexpected spend spikes, enabling proactive cost management and significant savings.
Alternatives
Agenta Alternatives
Agenta is an open-source LLMOps platform designed to help development teams build and manage reliable AI applications. It falls into the category of development tools focused on the operational lifecycle of large language models, providing a unified system for experimentation, evaluation, and deployment. Users may explore alternatives for various reasons, including specific budget constraints, the need for different feature sets like advanced monitoring or native CI/CD integration, or a preference for a managed service over self-hosted open-source software. Organizational requirements around scalability, security compliance, and existing tech stack compatibility also drive the search for other solutions. When evaluating alternatives, key considerations should include the platform's approach to collaborative experimentation, the robustness of its evaluation and testing frameworks, and its observability capabilities for production applications. The ideal tool should align with your team's workflow, support the LLM frameworks you use, and provide a clear path from prototype to stable, monitored deployment.
Fallom Alternatives
Fallom is an AI-native observability platform, a specialized category of development tool designed to monitor, debug, and govern production-level large language model and AI agent applications. Users may explore alternatives for various reasons, including budget constraints, specific feature requirements not covered by their current solution, or a need for a platform that integrates more seamlessly with their existing technology stack and operational workflows. When evaluating different solutions in this space, it is crucial to consider several key factors. The depth of tracing and granularity of data captured for each LLM interaction is fundamental for effective debugging. Equally important are the platform's scalability, its approach to data privacy and security, and the robustness of its compliance features, such as audit trails and consent tracking, which are essential for enterprise deployments. The ideal alternative should not only provide technical visibility but also align with your organization's long-term strategy for AI governance and cost management. It should empower teams to move from experimentation to reliable, controlled production deployments with confidence.