Friendli Engine
About Friendli Engine
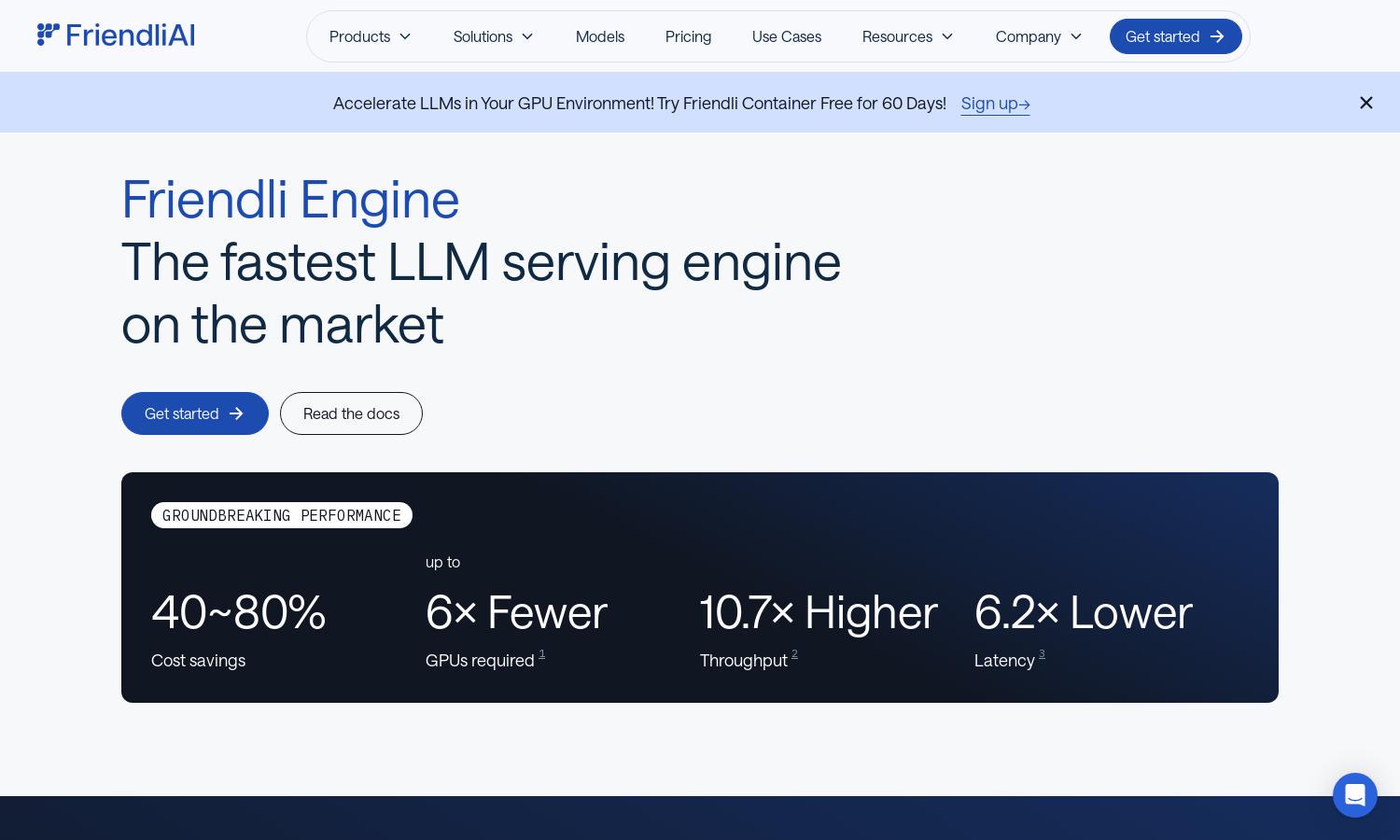
Friendli Engine is designed for developers seeking high-performance generative AI solutions. By harnessing cutting-edge technology like Iteration Batching and the Friendli DNN Library, this platform dramatically enhances LLM inference speed and efficiency. Its innovative features reduce costs while maintaining output quality, making AI innovation more accessible.
Friendli Engine offers a free trial for new users, with competitive pricing for subscription plans tailored to various needs. Each tier provides essential features, with increased support and resources at higher levels. Users benefit from upgrading, gaining access to advanced performance and optimizations that streamline AI model deployment.
The user interface of Friendli Engine is intuitive and innovative, facilitating easy navigation and model deployment. The layout promotes a seamless browsing experience, integrating user-friendly features that help developers and businesses efficiently utilize generative AI capabilities. Each tool is strategically positioned for quick access and streamlined workflows.
How Friendli Engine works
Upon joining Friendli Engine, users undergo a simple onboarding process, allowing them to set up their environment and access comprehensive documentation. Users can choose between different models to deploy, using the dedicated endpoints or container options. The platform's innovative technology allows for fast model inference, optimizing performance while simplifying the client experience with easy navigation and tools tailored for effective use.
Key Features for Friendli Engine
Iteration Batching Technology
Friendli Engine's Iteration Batching technology dramatically increases LLM inference throughput, achieving significantly higher performance than conventional methods. This unique feature optimizes resource utilization, making the platform ideal for users looking to enhance their generative AI workflows efficiently, ensuring timely and cost-effective outputs.
Multi-LoRA Model Support
Friendli Engine's support for multiple LoRA models on a single GPU simplifies LLM customization and deployment. This feature significantly enhances flexibility and efficiency, catering to users who require diverse LLM capabilities without the burden of managing numerous GPUs, effectively streamlining the generative AI process.
Friendli TCache
The Friendli TCache feature intelligently records and reuses computational results, optimizing Time to First Token (TTFT) significantly. By leveraging cached outcomes, Friendli Engine enables users to achieve faster LLM responses, making their applications more responsive while lowering computational demands and costs.








